Document Extraction
Die Dokumentenextraktion dient zum Auslesen von Belegdaten aus Dokumenten, wie Rechnungen oder Aufträgen. Ein Dokument wird in dieser Aktion über die Software maschinenlesbar gerendert, und die Logik von IRISXtract liest dieses dann aus, um als Ergebnis Indexdaten an xSuite Bus zu übergeben.
Der neue Standard PDF 2.0 wird sowohl für die Datenextraktion als auch für die Verwendung mit GdPicture (z. B. für das Rendern der Web-Viewer-Images) unterstützt
Die folgenden Einstellungen stehen dem Administrator für die Konfiguration der Document-Extraktion-Aktionen zur Verfügung.
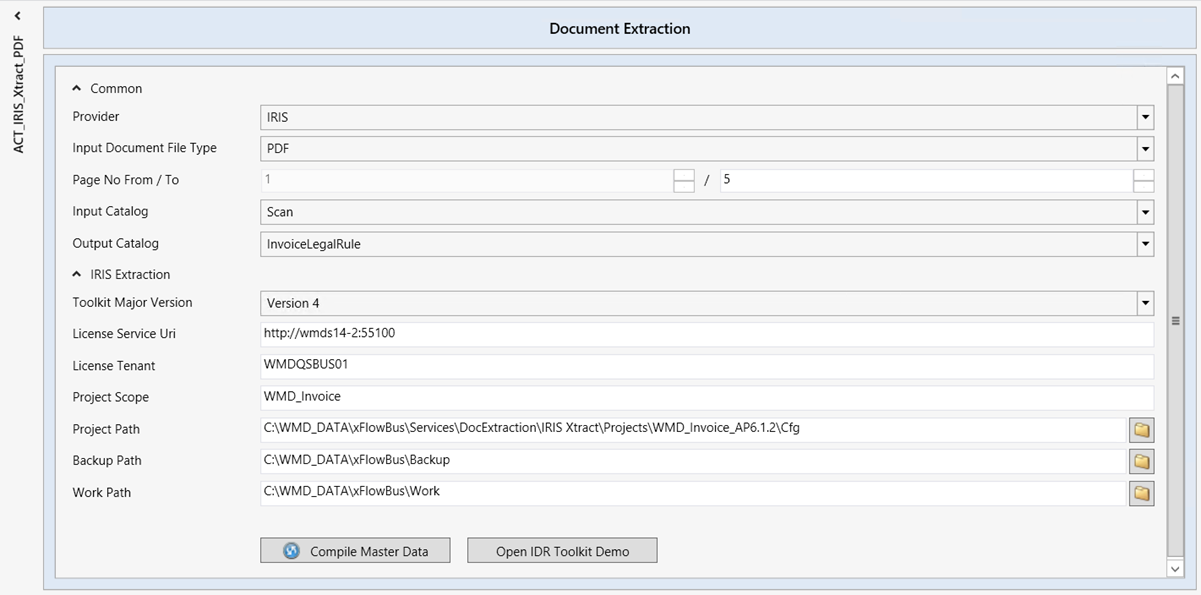 |
Bereich | Parameter | Beschreibung |
|---|---|---|
Common | Provider | Anbieter der Datenextraktionslösung. Im Moment steht als Provider (Anbieter) der Datenextraktionslösung nur IRIS zur Verfügung. |
Input Document File Type | Hier kann das Format des eingehenden Dokuments angegeben werden, welches für die Datenextraktion genutzt werden soll. Zur Auswahl stehen PDF oder TIFF. | |
Page No From / To | Hier kann angegeben werden, auf welchen Seiten (Von Seite .../Bis zur Seite...) die Datenextraktion Indexdaten lesen sollen. Im Standard werden maximal die ersten fünf Seiten gelesen, um die Verarbeitungsdauer der Datenextraktion gering zu halten. | |
Input Catalog | Eingangsfeldkatalog vor der Datenextraktion. Dieser Katalog ist in xSuite Bus angelegt und wird für das Feldmapping mitgeführter Feldwerte genutzt. Im Standard ist dieses der Scan-Katalog. | |
Output Catalog | Ausgangsfeldkatalog nach der Datenextraktion. Dieser Katalog ist in xSuite Bus angelegt und wird für das Feldmapping der Datenextraktionsergebnisse genutzt. Im Standard ist dieses der Feldkatalog InvoiceLegalRule. | |
IRIS Extraction | Toolkit Major Version | Zeigt die IDR-Toolkit-Version. |
License Service Uri | Verbindung zum IRIS License Webservice, der die Lizenzen von der I.R.I.S. AG verwaltet. Die Lizenzinformationen können unter Customer Clients → Licensing eingesehen werden. | |
License Tenant | Name der Lizenz, die zur Datenextraktion herangezogen werden soll. Dieser muss so auch im IRIS License Server angelegt sein. So ist es möglich, unterschiedliche Lizenzen unterschiedlichen Nutzern zuzuweisen. | |
Project Scope | Name des Datenextraktionsprojekts, welches zur Datenextraktion herangezogen werden soll. HinweisBei der Verwendung mehrerer IRISXtract-Aktionen muss im Feld Project Scope pro Aktion jeweils ein unterschiedlicher Wert angegeben werden. | |
Project Path | Die Datenextraktionsprojekte werden während der Installation im Ordner | |
Backup Path | Ablageort der Datenextraktionsergebnisse für eine eventuelle spätere Betrachtung. Daten werden dort hinterlegt, bis sie vom xSuite-Bus-System-Clean-up-Service gelöscht werden. | |
Work Path | Ablageort für die Datenextraktionsergebnisse für die Zeit der Ergebnisermittlung. Der Inhalt wird nach der Übergabe der Extraktionsdaten gelöscht. | |
IDR Subprocess Termination | Ressourcenschonende Verarbeitung der Datenextraktion Wenn die Checkbox Terminate subprocesses after document processing aktiviert ist, werden bei der Bearbeitung eines Dokumentes die benötigten Unterprozesse jedes Mal neu geladen und wieder beendet. Dies dient der Ressourcenschonung und Stabilität des Systems. HinweisDiese Checkbox ist nur für die IDR-Toolkit-Version 5.1 oder höher relevant. | |
Compile Master Data | Manuelles Kompilieren der Stammdaten mit dem IRIS-Datenextraktionsprojekt. Weitere Informationen finden Sie unter Compile Master Data. | |
Open IDR Toolkit Demo | Hier kann eine von der I.R.I.S. AG zur Verfügung gestellte Demo-Software geladen werden, die es dem Administrator ermöglicht, die Qualität der Stammdaten und der Leseergebnisse zu testen. In den xSuite Bus-Einstellungen Settings → Files → IDR Toolkit Demo wird der Ablageort dieser Software angegeben. |
Compile Master Data
Die Leseergebnisse des IRIS-Datenextraktionsprojekts sind stark abhängig von der Qualität der Stammdaten. Diese Stammdaten werden in regelmäßigen, einzuplanenden Abständen ausgelesen und in die Projektstruktur übernommen.
Normalerweise wird das Kompilieren der Stammdaten in einem Task eingeplant und findet dann zu einem Zeitpunkt statt, wenn der Server nur eine geringe Auslastung hat.
Dieses Kompilieren der Stammdaten (Compile Master Data) kann auch manuell ausgeführt werden, wenn zum Beispiel ungeplant neue Stammdaten angelegt wurden.
Die xSuite Group GmbH empfiehlt den folgenden Ablauf für die Kompilierung:
Aktualisieren Sie die Stammdaten mit aktuellen Informationen aus dem Zielsystem, z. B. Kreditorenstammdaten (
Master_Creditor.csv) oder Bestelldaten (Master_Transaction.csv).Stoppen Sie die Dienste für die Datenextraktion.
Klicken Sie auf den Button Compile Master Data.
➣ Die Stammdaten werden kompiliert.
Starten Sie die Dienste für die Datenextraktion.